
- Por María Dueñas
- ·
- Publicado 01 Mar 2024
¿Cómo aplicar TDD? - Nivel avanzado
Si tienes mucha experiencia implementando TDD, tu plan de aprendizaje debería centrarse en profundizar tu comprensión de los principios avanzados,..

Este artículo es parte de una serie de publicaciones sobre anti patrones en TDD. El primero capítulo cubrió: the liar, excessive setup, the giant and slow poke. En la industria, generalmente hablamos sobre cómo se deben hacer las cosas, pero a veces nos olvidamos cómo podemos aprender con los errores que cometemos al escribir pruebas unitarias.
Este blog es el segundo de la serie donde nos enfocaremos en cuatro anti patrones más, llamados: The mockery, The inspector, The generous leftovers y The local hero. Cada uno se centra en un aspecto específico del código que dificulta las pruebas.
Potencialmente, una de las causas principales por las que las empresas argumentan que no tienen el tiempo necesario para crear soluciones guiadas por pruebas.
Si lo prefieres puedes ver el contenido de este workshop en formato video aquí.
En la encuesta que llevamos a cabo, hemos preguntado: "La empresa en que trabajo o trabajé anteriormente argumentan que TDD requiere demasiado tiempo para terminar una tarea y los equipos no tienen tiempo para ello."
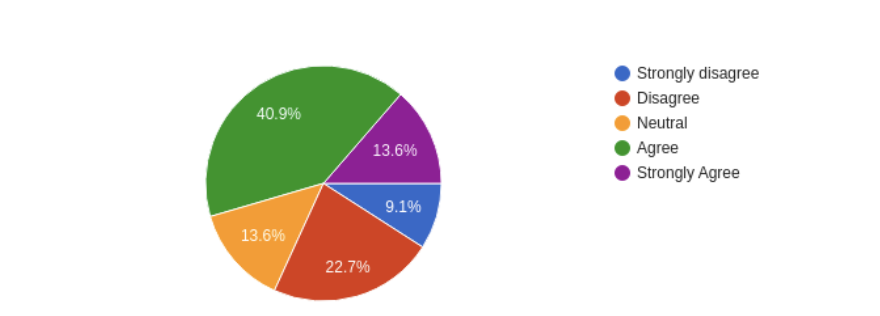
Más del 50% de los encuestados coincidieron en que en las empresas para las que han trabajado, se da la idea de que TDD requiere más tiempo para terminar una tarea.
Más del 50% de los encuestados coincidieron en que en las empresas para las que han trabajado, se da la idea de que TDD requiere más tiempo para terminar una tarea.
Se requeriría más investigación para evaluar por qué ese es el caso y por qué los participantes tienen esta percepción. Por lo tanto, incluso sin datos, podríamos inferir que, si enfrenta dificultades para escribir las pruebas o mantenerlas, tomará más tiempo. Por otro lado, la prevención de esas dificultades (anti patrones) podría ser una forma de integrar la cultura de prueba y evitar dicha percepción.
/** * Two constructor dependencies, both need to be * mocked in order to test the process method. */class PaymentService( private val userRepository: UserRepository, private val paymentGateway: PaymentGateway) { fun process( user: User, paymentDetails: PaymentDetails ): Boolean { if (userRepository.exists(user)) { return paymentGateway.pay(paymentDetails) } return false }With test:
class TestPaymentService { private val userRepository: UserRepository = mockk() private val paymentGateway: PaymentGateway = mockk() private val paymentService = PaymentService( userRepository, paymentGateway ) @Test fun paymentServiceProcessPaymentForUser() { val user: User = User() every { userRepository.exists(any()) } returns true every { paymentGateway.pay(any()) } returns true // setting up the return for the mock assertTrue(paymentService.process(user, PaymentDetails())) // asserting the mock }}<?php/* skipped code */class Assembly{ /* skipped code */ public function __construct( FindVersion $findVersion, FileRepository $fileRepository, string $branchName, FilesToReleaseRepository $filesToReleaseRepository ) { $this->findVersion = $findVersion; $this->fileRepository = $fileRepository; $this->branchName = $branchName; $this->filesToReleaseRepository = $filesToReleaseRepository; } public function getFilesToWriteRelease(): array { return $this->filesToWriteRelease; } public function setFilesToWriteRelease(array $filesToWriteRelease) { $this->filesToWriteRelease = $filesToWriteRelease; return $this; } public function packVersion(): Release { $filesToRelease = $this->getFilesToWriteRelease(); if (count($filesToRelease) === 0) { throw new NoFilesToRelease(); } $files = []; /** @var File $file */ foreach ($filesToRelease as $file) { $files[] = $this->fileRepository->findFile( $this->findVersion->getProjectId(), sprintf('%s%s', $file->getPath(), $file->getName()), $this->branchName ); } $versionToRelease = $this->findVersion->versionToRelease(); $release = new Release(); $release->setProjectId($this->findVersion->getProjectId()); $release->setBranch($this->branchName); $release->setVersion($versionToRelease); $fileUpdater = new FilesUpdater($files, $release, $this->filesToReleaseRepository ); $filesToRelease = $fileUpdater->makeRelease(); $release->setFiles($filesToRelease); return $release; }}public class Employee { private Integer id; private String name;}@Testpublic void whenNonPublicField_thenReflectionTestUtilsSetField() { Employee employee = new Employee(); ReflectionTestUtils.setField(employee, "id", 1); assertTrue(employee.getId().equals(1));}const mockFn = jest.fn(); // setting up the mockfunction fnUnderTest(args1) { mockFn(args1);}test('Testing once', () => { fnUnderTest('first-call'); expect(mockFn).toHaveBeenCalledWith('first-call'); expect(mockFn).toHaveBeenCalledTimes(1);});test('Testing twice', () => { fnUnderTest('second-call'); expect(mockFn).toHaveBeenCalledWith('second-call'); expect(mockFn).toHaveBeenCalledTimes(1);});La primera prueba que llama a la función bajo el test pasará, pero la segunda fallará. La razón es no limpiar la ejecución del mock. La prueba falla apuntando que el mockFn fue llamado dos veces. Conseguir el flujo como debería es tan fácil como:
test('Testing twice', () => { mockFn.mockClear(); // clears the previous execution fnUnderTest('second-call'); expect(mockFn).toHaveBeenCalledWith('second-call'); expect(mockFn).toHaveBeenCalledTimes(1);});import { Component } from 'react';import Button from '../../buttons/primary/Primary'; import '../../../../scss/shake-horizontal.scss';import './survey.scss'; const config = { surveyUrl: process.env.REACT_APP_SURVEY_URL || '',} const survey = config.surveyUrl; const mapStateToProps = state => ({ user: state.userReducer.user,}); export class Survey extends Component { /* skipped code */ componentDidMount = () => { /* skipped code */} onSurveyLoaded = () => { /* skipped code */} skipSurvey = () => { /* skipped code */} render() { if (this.props.user.uid && survey) { return ( <div className={`w-full ${this.props.className}`}> { this.state.loading && <div className="flex justify-center items-center text-white"> <h1>Loading...</h1> </div> } <iframe src={this.state.surveyUrl} title="survey form" onLoad={this.onSurveyLoaded} /> { !this.state.loading && this.props.skip && <Button className="block mt-5 m-auto" description={this.state.buttonDescription} onClick={this.skipSurvey} /> } </div> ); } return ( <div className="flex justify-center items-center text-white"> <h1 className="shake-horizontal">Something wrong happened</h1> </div> ); }} /* skipped code */Y aquí el test case para estos componentes:
import { mount } from 'enzyme';import { Survey } from './Survey';import { auth } from '../../../../pages/login/Auth';import Button from '../../buttons/primary/Primary'; describe('Survey page', () => { test('should show up message when survey url is not defined',() => { const wrapper = mount(<Survey user= />); const text = wrapper.find('h1').text(); expect(text).toEqual('Carregando questionário...'); }); test('should not load survey when user id is missing', () => { const wrapper = mount(<Survey user= />); const text = wrapper.find('h1').text(); expect(text).toEqual('Ocorreu um erro ao carregar o questionário'); }); test('load survey passing user id as a parameter in the query string', () => { const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' }; const wrapper = mount(<Survey user={user} />); const url = wrapper.find('iframe').prop('src'); expect(url.includes(auth.user.uid)).toBe(true); }); test('should not up button when it is loading', () => { const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' }; const wrapper = mount(<Survey user={user} />); expect(wrapper.find(Button).length).toBe(0); }); test('should not up button when skip prop is not set', () => { const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' }; const wrapper = mount(<Survey user={user} />); expect(wrapper.find(Button).length).toBe(0); }); test('show up button when loading is done and skip prop is true', () => { const user = { uid: 'uhiuqwqw-k-woqk-wq--qw' }; const wrapper = mount(<Survey user={user} skip={true} />); wrapper.setState({ loading: false }); expect(wrapper.find(Button).length).toBe(1); });});
En este segundo episodio, cubrimos cuatro antipatrones más que se interponen en nuestro camino mientras desarrollamos aplicaciones guiadas por pruebas. Cuando tales problemas llegan a la base del código, es normal percibir que las pruebas, "ralentizarán la entrega de una tarea en comparación con ninguna prueba". Pero, por otro lado, también puede ser un arma de doble filo, en la que no tener las pruebas podría ralentizarte aún más.
The mockery fue el anti patrón más popular, y las respuestas de la encuesta mostraron que el mal uso de los test doubles (o, más conocidos como mocks) puede ser una fuente de problemas. También vimos que la reflexión podría ser un problema mientras que probar y restablecer el estado es importante para mantener el conjunto de las pruebas nítido. Finalmente, cubrimos el problema en el que el conjunto de las pruebas solo se ejecuta en la máquina de los desarrolladores (o para el estándar actual, ¿en la imagen docker de los desarrolladores?).
En general, esperamos que esto se resuma con el episodio anterior y que mantenga su conjunto de pruebas funcionando sin problemas.
Si tienes mucha experiencia implementando TDD, tu plan de aprendizaje debería centrarse en profundizar tu comprensión de los principios avanzados,..

Para un desarrollador con un nivel intermedio en Desarrollo Guiado por Pruebas (TDD), el objetivo es profundizar en la comprensión de los..

Si estás dando tus primeros pasos en el Desarrollo Dirigido por Pruebas (TDD) y quieres empezar a aplicarlo en tus proyectos, entonces estás en el..