
Você pode ter encontrado software que não é facilmente testável e, com isso, quero dizer software que não é testado desde o início. Você pode até ter tentado testá-lo, mas não conseguiu. Não se preocupe, o software em que o teste é uma reflexão tardia nunca será tão testável quanto o software projetado para ser testado desde o início.
Neste post, vou explorar como você pode abordar o teste de software onde o teste é uma reflexão tardia. Abordarei o contexto que você precisa coletar, um exemplo simples de Golden Master Testing e uma implementação não padronizada do padrão Golden Master.
Além disso, compartilharei com você um exemplo prático de como abordamos esse desafio com um de nossos clientes - e os resultados que conseguimos alcançar.
Por onde você começa ao trabalhar com código que não foi criado para ser testado?
Como consultoria de software, a Codurance trabalha com muitos clientes e códigos que estão em diferentes estágios ou estados. No cenário que vou compartilhar com vocês hoje, estávamos trabalhando com um cliente que tinha código de produção com pouco ou nenhum teste automatizado.
Em primeiro lugar, era importante concordarmos que uma “rede de segurança” deveria estar em vigor, onde um conjunto de testes automatizados poderia fornecer feedback sobre se as alterações no código de produção alteraram seu comportamento.
Receber esse tipo de feedback desde o início é importante, especialmente porque confiar em testes manuais resultará em feedback lento. Esse feedback lento pode não chegar a um desenvolvedor até horas, dias, semanas depois de fazer uma alteração.
Características comuns do código legado que dificultam o teste
O código de produção de nosso cliente tinha várias características que você pode esperar de um software escrito há alguns anos e que foi adicionando funcionalidades ao longo do tempo. Tudo isso é importante entender para apreciar melhor como tomamos decisões.
Aqui estão algumas dessas características e outros fatos pertinentes que ajudaram a moldar nossa solução.
Fortemente dependente de um banco de dados
A parte específica do código que estávamos testando dependia muito do banco de dados (DB). Com isso, quero dizer que ele é executado em um cronograma e consultará o banco de dados para ver se há entrada para processar. Nesse sentido, o banco de dados fornece a entrada para o código que queremos testar. E, claro, isso significa que precisávamos fornecer a entrada para o banco de dados, mas mais sobre isso depois.
Também é importante destacar que o design do sistema significa que o banco de dados é realmente parte integrante de como o código de produção é executado, controlando quais ramificações do código são executadas, por exemplo. Não vai demorar muito para fazer a conexão entre essa afirmação e o impacto em como o software é testado. Sim, de fato você está pensando que muitos dados precisarão ser colocados no banco de dados, antes de invocar o código de produção.
Em seguida, quero falar sobre a saída - usando o termo livremente. Digo isso porque o código de produção processa a entrada e grava os dados de volta no banco de dados, e aqui vou me referir a isso como “saída”, embora não seja, mas não quero ser pego em um debate filosófico sobre se isso é realmente "entrada" para o banco de dados. Portanto, para resumir o último ponto, o comportamento observável dessa parte do sistema é feito observando o efeito no banco de dados após a conclusão do código de produção.
Grande base de código que cresceu ao longo do tempo
O código é grande e foi adicionando funcionalidades ao longo do tempo. A redação é deliberada, pois o design não evoluiu necessariamente, mas um novo código foi adicionado e espalhado por todo o código existente. O que resta é grande e complexo, com algumas classes e métodos muito grandes.
Aqui, o tamanho do código é importante, pois mais código neste caso significava mais ramificações possíveis (execução de código, nada a ver com Git). E por causa do tamanho, você pode acabar fazendo uma alteração na linha 2.000 e impactar algo que acontece na linha 10.000.
O que tudo isso significa é que, como o código não foi projetado para ser testado quando foi criado, não poderíamos empregar facilmente as técnicas que usaríamos normalmente, pois isso provavelmente envolveria fazer alterações no código grande e complexo subjacente. Na verdade, fazer isso na ausência dessa “rede de segurança” tornaria essas mudanças potencialmente de alto risco, o que era extremamente indesejável nesse domínio específico.
Código antigo (que não envelheceu bem)
Outra parte importante do contexto é a idade do código. Todos nós sabemos que é incomum um software envelhecer como o vinho ou queijo, e quando nos referimos a “código legado”, não estamos elogiando o legado que foi deixado por pessoas antes de nós.
Como mencionado anteriormente, o código foi adicionado ao longo de muitos anos e o código pode conter ramificações mortas. Isso é extremamente importante, pois sustenta por que solicitamos dados da produção como entradas, além de obter especialistas de domínio para categorizar o comportamento e exemplos de origem que testaram esse comportamento.
O contexto e o ambiente são essenciais para permitir o teste no código legado
Talvez você já tenha percebido que essa não era uma situação para o teste padrão do Golden Master. Tivemos que trabalhar iterativamente em direção a uma solução, com base no levantamento do ambiente e na absorção de todo o contexto e fatos. Mas vamos primeiro fornecer uma atualização sobre os testes Golden Master.
O que fazer quando você não pode usar o teste Golden Master padrão
Antes de pular para a abordagem e nossa solução, pensei que valeria a pena uma pequena atualização sobre o Golden Master Testing, trabalhando com um exemplo simples.
Golden Master Testing - uma atualização rápida
Para aqueles de vocês mais familiarizados com a técnica Golden Master, você normalmente verá coisas como as abaixo na literatura:
Registre as saídas, para um conjunto de entradas fornecidas
Isso é muito simples e, se você mesmo os escreveu, provavelmente tinha um arquivo de texto com as entradas e um arquivo de texto com todas as saídas.

Onde sua entrada pode parecer:
1 Name: Sam, Age: 1052 Name: Bob, Age: 343 Name: Linda, Age: 26
E a saída:
1 Can retire: true
2 Can retire: false
3 Can retire: false
É simples e cada linha corresponde a um único cenário. Por exemplo, quando o código de produção obtém Sam e ele tem 105 anos, podemos ver que o código de produção diz que ele pode se aposentar.
Todos nós amamos código simples e a simplicidade acima, mas não tivemos o luxo de escrever uma implementação tão simples. No entanto, queríamos avaliar se uma abordagem Golden Master realmente funcionaria e, mais importante, valeria o investimento.
No contexto de nosso cliente, essa abordagem era simples demais para funcionar. Em vez disso, tivemos que adotar uma abordagem personalizada que começou com testes manuais.
Comece experimentando um teste manual
Começamos a escrever um único teste escrito à mão. Você pode comparar isso com uma única linha do arquivo de texto mencionado acima, que geralmente se correlaciona com um único cenário. No entanto, ao contrário do exemplo simples descrito anteriormente, o nosso não era uma única linha. Para este cenário único, exigimos a configuração de várias tabelas no banco de dados, que deveriam ser inseridas em uma ordem específica, exigindo uma orquestração cuidadosa, dadas as restrições do banco de dados.
Isso equivalia a mergulharmos os pés na água e era necessário para obter feedback sobre nossa abordagem. Durante esse experimento, concluímos (entre outras coisas) que esses testes eram lentos para escrever e, por isso, decidimos explorar se havia uma maneira melhor.
Levantar hipóteses, identificar oportunidades e experimentar
Você pode ter ouvido conselhos como “você não deve automatizar imediatamente”, e este é um conselho sensato. Estávamos seguindo isso quando começamos a escrever os testes manualmente. Conforme mencionado anteriormente, havia várias tabelas que tínhamos que configurar antes de invocar o código de produção. Agora, identificamos que grandes partes dessa configuração podem ser determinadas desde a entrada até o código de produção.
Então nos perguntamos:
Podemos gerar testes, usando a entrada para a configuração necessária?
Se fôssemos capazes de fazer isso, economizaríamos o trabalho dispendioso de criar a configuração a partir das informações da entrada, repetidas vezes, para cada cenário. Nesse momento, imagine ler um pedaço de papel e inserir partes dessa informação digitalmente por meio de um computador. Foi assim que me senti.
Experimentamos e descobrimos que essa abordagem de criar automaticamente a configuração a partir da entrada é promissora. Então, apoiamos essa abordagem e continuamos nessa jornada.
Uma solução mais inteligente e automatizada
Escolhemos registrar o que o código de produção fez ao ver o efeito que teve no banco de dados. Em nosso contexto, o banco de dados é o núcleo, então isso era perfeitamente razoável.
O que isso significava era que executaríamos o código de produção com cada entrada e capturaríamos o que acontecia com o banco de dados (ou seja, os efeitos colaterais).
Exemplo prático de teste de código legado dependente de um banco de dados
Aqui, mostrarei o que fizemos para testar o código herdado capturando alterações no banco de dados.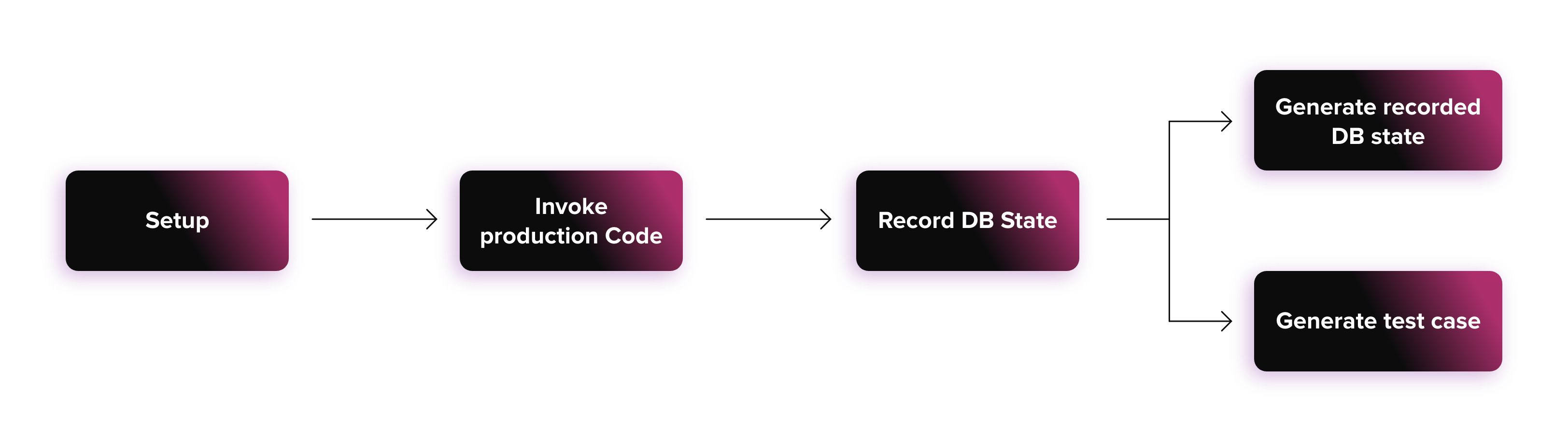
O exemplo acima mostra uma visão muito simplificada de como o comportamento do código de produção é capturado e como os testes são gerados.
Vamos nos aprofundar um pouco mais em cada uma dessas etapas, para descrever com mais detalhes o que elas estão fazendo.
Configuração
Objetivo - configurar o “mundo” para que o código de produção seja executado conforme o esperado
Exemplos - inserir dados no banco de dados, provisionar um servidor FTP fictício
Invocar código de produção
Objetivo - acionar parte do código de produção, de maneira representativa de como ele é realmente usado na produção
Exemplos - invocar o método runSomething() na classe chamada TheLegacyCode
Registrar estado do banco de dados
Objetivo - identificar em quais tabelas foram gravadas e capturar o conteúdo dessas tabelas
Esta etapa é bastante específica e pode assumir várias formas. Forneci um exemplo concreto para simplificar.
Gerar estado de banco de dados gravado
Objetivo - armazenar o estado do banco de dados após invocar o código de produção. Isso forma a base das asserções que são usadas para verificar se o estado do banco de dados foi alterado quando os casos de teste são executados.
Gerar caso de teste
Objetivo - gerar um arquivo que represente um teste e tenha todas as informações necessárias para localizar a entrada e a saída esperada (para usar esse termo livremente) para um determinado cenário.
Código legado grande e complexo centrado em banco de dados pode ser testado
Antes de adicionarmos este conjunto de testes, muitos provavelmente disseram “este código não pode ser testado”, mas fornecemos uma maneira de provar que ele pode ser testado e fornecer opções às pessoas se elas se encontrarem em uma situação semelhante.
Descobrimos que a abordagem que adotamos tinha várias vantagens, incluindo:
Feedback mais rápido
Conforme declarado na literatura muitas vezes, obter feedback mais rapidamente é sempre desejável, e este conjunto de testes forneceu isso.
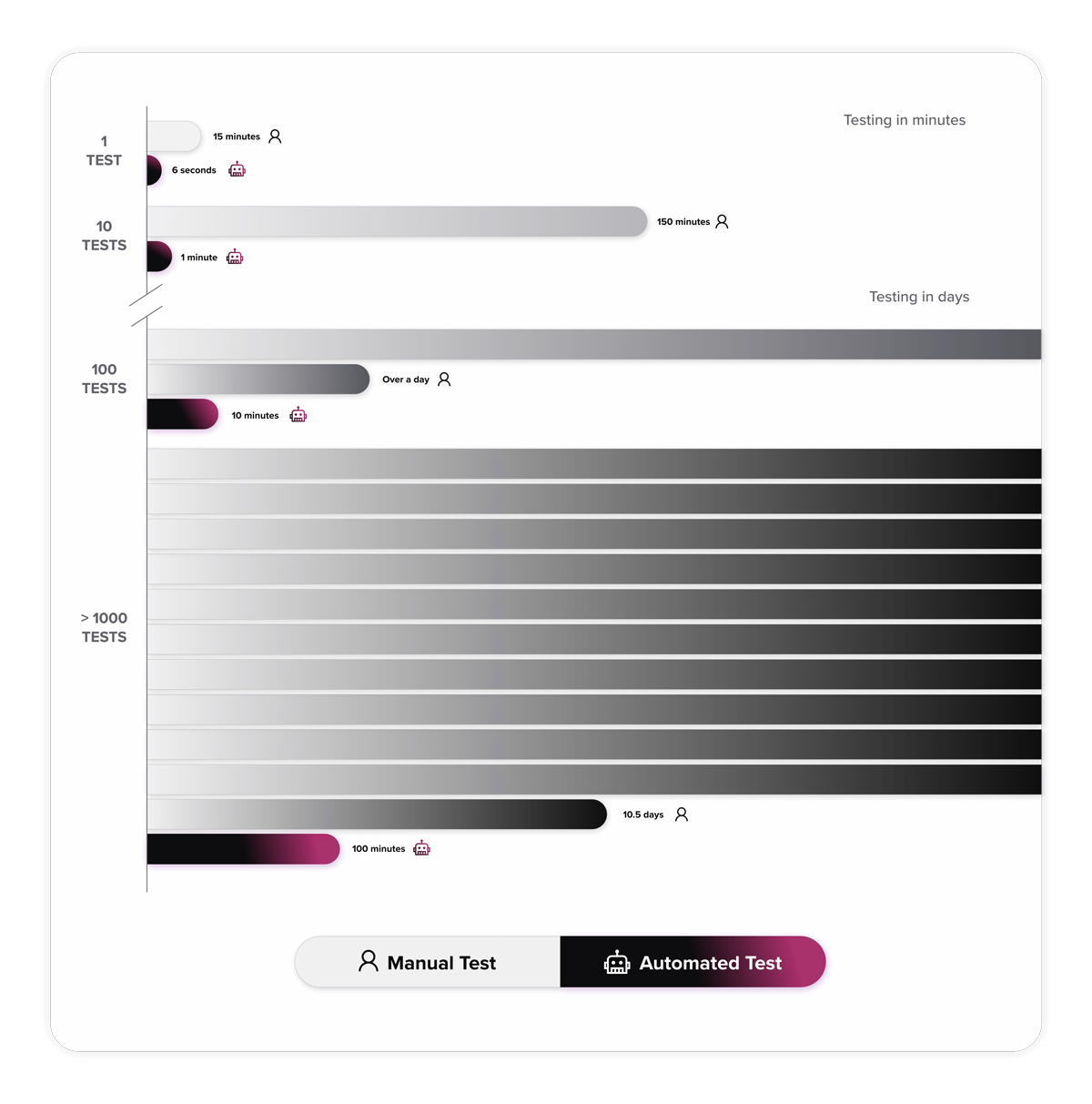
A economia de tempo é realmente surpreendente. Leva 2,5 horas para um testador manual executar 10 testes manuais, enquanto leva apenas um minuto para executar 10 versões automatizadas desses testes manuais. Você aprecia isso ainda mais quando entende que o Test Suite tem cerca de 1.000 testes e executar 1.000 testes manuais levaria 10,5 dias (para uma pessoa que trabalha 24 horas por dia), enquanto os testes automatizados serão concluídos em 1 hora e 40 minutos.
A economia de tempo é significativa, mas o teste automatizado também permite mais flexibilidade para os desenvolvedores executarem testes sob demanda sempre que quiserem. Infelizmente, você não pode fazer o mesmo com um testador manual, toque no teclado três vezes e eles aparecem.
 Maior flexibilidade
Maior flexibilidade
Nossa abordagem específica de geração desses testes significava que poderíamos girar muito mais rápido do que criá-los manualmente. Por exemplo, se precisássemos testar em uma tabela anteriormente desconhecida, poderíamos configurá-la na ferramenta e, em seguida, gerar novamente todos os testes, onde agora a nova tabela é capturada no “estado do banco de dados gravado”. Isso foi muito útil, especialmente porque não tínhamos todo o conhecimento inicial e poderíamos expandir nossos testes à medida que nosso conhecimento aumentasse.
Oportunidade de introduzir a automação
Pode parecer que estou afirmando o óbvio, mas essa foi uma das primeiras instâncias em que esse código realmente teve algum tipo de teste automatizado. Em particular, esses testes foram direto ao cerne dessa parte do sistema e testaram a lógica central, algo que não havia acontecido antes.
Teste o código legado com mais confiança
Encontramos uma maneira de trabalhar iterativamente para estabelecer um conjunto de testes Golden Master como um meio de alterar o código subjacente com mais confiança e eliminar o medo que pode se formar. O cliente realmente comentou sobre como eles não têm mais o medo que já tiveram, e esse medo se dissipou.
Uma coisa importante a destacar é que, depois de estabelecer uma suíte Golden Master, você pode começar a modernizar a base de código herdada com confiança.
Ao começar a modernizar a base de código e adicionar testes mais abaixo na pirâmide (por exemplo, testes de unidade), você obterá um feedback mais rápido e se tornará menos dependente apenas dos testes Golden Master.
Como sempre, o contexto é importante e espero que você entenda que todas as técnicas têm um tempo e um lugar, e até mesmo como essas técnicas são aplicadas dependerá consideravelmente do contexto.
O compartilhamento de conhecimento é importante e adoraríamos ouvir suas experiências com o teste de código legado.