Commits firmados: el por qué y el cómo
En nuestro último post de nuestra serie "Píldoras técnicas sobre Platform Engineering: más allá de lo que encuentras en la documentación", hablamos..

Traemos un capítulo más de nuestra serie "Píldoras técnicas sobre Platform Engineering: más allá de lo que encuentras en la documentación", donde el equipo de Platform Engineering de Codurance compartimos píldoras de conocimiento sobre cómo abordamos situaciones cotidianas. En el post anterior hablábamos de la Configuración de DMS para DocumentDB, en especial qué pasa con los índices.
Hoy compartiremos cómo gestionar un volumen masivo de logs a la hora de analizar una incidencia de seguridad. Acompáñanos en este viaje donde transformaremos objetos de S3 utilizando una arquitectura simple y flexible, soportada enteramente por servicios manejados de AWS.
Los logs son recursos clave a la hora de entender qué está pasando entre bastidores, pero es tan importante disponer de ellos como extraer la información clave para tomar las decisiones adecuadas, especialmente cuando contamos con enormes cantidades de información. En este blog detallaremos nuestro enfoque al asistir a nuestros clientes a la hora de analizar actividades sospechosas en la red, facilitando una respuesta efectiva ante posibles incidencias de seguridad.
GuardDuty es un servicio de AWS que ofrece detección de amenazas utilizando algoritmos de aprendizaje automático y protección proactiva ante posibles amenazas. Cada resultado debe analizarse con atención para confirmar si es un ataque o, en su defecto, identificar falsos positivos. Un ejemplo práctico es cuando una instancia de EC2 tiene actividad sospechosa: es importante investigar si ha habido algún intento por parte del atacante de acceder a otros recursos dentro de la VPC. ¿Cómo podemos saberlo basándonos en los logs de lujo de datos de la VPC (VPC Flow Logs)?
La idea era mantenerlo sencillo, de forma que unas pocas líneas de Python en una función Lambda obtuviesen los objetos relevantes y lo mandasen a nuestra plataforma de visualización de datos (DVP).

En menos de una hora estaba funcionando, pero no tardamos en darnos cuenta de lo difícil que iba a ser leer los datos, como podemos ver en este ejemplo de una entrada de los logs:
5 52.95.128.179 10.0.0.71 80 34210 6 1616729292 1616729349 IPv4 14 15044 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 19 52.95.128.179 10.0.0.71 S3 - - ingress OK5 10.0.0.71 52.95.128.179 34210 80 6 1616729292 1616729349 IPv4 7 471 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 3 10.0.0.71 52.95.128.179 - S3 8 egress OK
Tuvimos que eliminar esos IDs y reemplazarlos con etiquetas que pudiésemos interpretar:
|
Campo |
Etiqueta |
|
|
Interface description |
|
|
Subnet name |
|
|
VPC name |
|
|
Subnet Name |
|
|
Subnet Name |
En este blog no describiremos el proceso de asociación de las etiquetas. A efectos prácticos, consideraremos la existencia de un proceso externo que toma esta información y la hace accesible a nuestra Lambda.
Pudimos probar la solución con un fichero sin problemas, pero al hacer una prueba durante una hora alcanzamos el timeout de 15 minutos de Lambda… ¡y ni siquiera llegó a procesar todos los logs!
Teníamos que procesar cada archivo de forma individual, pero cómo podríamos gestionar una gran cantidad de ellos de forma eficiente? La respuesta está en AWS Step Functions.
AWS Step Functions tiene una característica llamada Map State, que nos permite iterar de forma eficiente sobre un conjunto de objetos de S3. Cada uno dispara una ejecución de Lambda independiente:
3. La función Lambda comienza obteniendo el contenido del objeto desde S3.
4. Por cada entrada de log, reemplaza los poco amigables IDs por nuestras etiquetas legibles.
5. Finalmente, envía los logs enriquecidos a la DVP de nuestra elección.
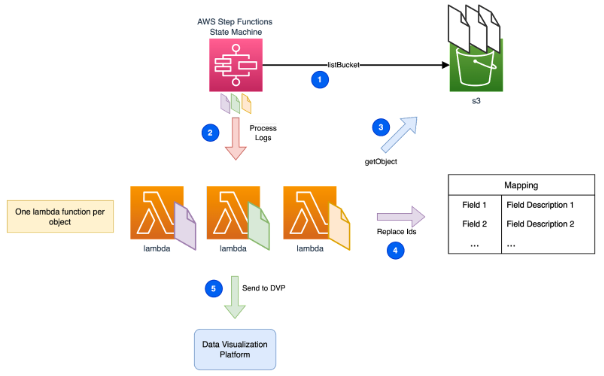
Tenemos a tu disponibilidad un módulo de terraform para probar este escenario de forma simplificada.
La solución presentada ofrece un enfoque directo que no necesita experiencia previa en Lambda, Python o el servicio de Step Functions, asegurando facilidad de uso sin dependencia de los conocimientos técnicos.



