Signed git commits. The why and the how
In our last post of our series "Technical pills about Platform Engineering: beyond what you find in the documentation", we talked about Leveraging..

We have a new chapter of our series “Technical pills about Platform Engineering: beyond what you find in the documentation”, where the Codurance Platform Engineering team shares pieces of knowledge regarding issues we face on our day to day operations. In the previous post we were talking about DMS configuration for DocumentDB.
Today, we're sharing how we handle a massive volume of logs in response to a security incident analysis. Join us on this journey to effortlessly transform S3 objects using a simple, flexible architecture built entirely on AWS-managed services.
Logs are crucial resources for understanding what's happening behind the scenes, but equally important as having them is our ability to extract valuable information from massive amounts of data and use it to support our decisions better. In this article, we detail our approach to assist our clients with analysing suspicious network activity, enabling them to respond effectively to security incident findings.
GuardDuty is an exceptional service that offers threat detection using advanced machine learning algorithms and proactive protection against potential threats. Every finding should be carefully analysed to confirm an attack or to identify false positives. One practical example is when an EC2 instance has suspicious activity. It is crucial to investigate whether there was any lateral movement from the attacker to access other resources within VPC. How do we propose it based on the existing VPC Flow Logs?
We kept things simple so that a few lines of Python code in a Lambda function would get the relevant objects and send them to a Data Visualisation Platform (DVP).

We made it work in less than one hour, but we rapidly discovered how hard it would be to read log data, as this example proves…
Example of a VPC Flow Log entry
5 52.95.128.179 10.0.0.71 80 34210 6 1616729292 1616729349 IPv4 14 15044 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 19 52.95.128.179 10.0.0.71 S3 - - ingress OK5 10.0.0.71 52.95.128.179 34210 80 6 1616729292 1616729349 IPv4 7 471 123456789012 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-0c50d5961bcb2d47b eni-1235b8ca123456789 ap-southeast-2 apse2-az3 - - ACCEPT 3 10.0.0.71 52.95.128.179 - S3 8 egress OK
We had to eliminate these IDs and replace them with valuable information we could easily understand.
|
Field |
Proposed label |
|
|
Interface description |
|
|
Subnet name |
|
|
VPC name |
|
|
Subnet Name |
|
|
Subnet Name |
This article won’t describe the mapping process for the sake of simplification. Consider the existence of an external process that gets this data and makes it accessible to our Lambda.
We tested this solution with a single file, and everything looked good. Still, when we did the same, but now for an entire hour, we hit the 15-minute timeout (Lambda), and most disappointing, we didn’t even process half of the logs.
We had to process each file individually, but how could we efficiently manage hundreds or thousands of them? The answer is AWS Step Functions!
AWS Step Functions has a feature called Map State that enables us to iterate efficiently over a collection of S3 objects. Each one targets a single Lambda execution.
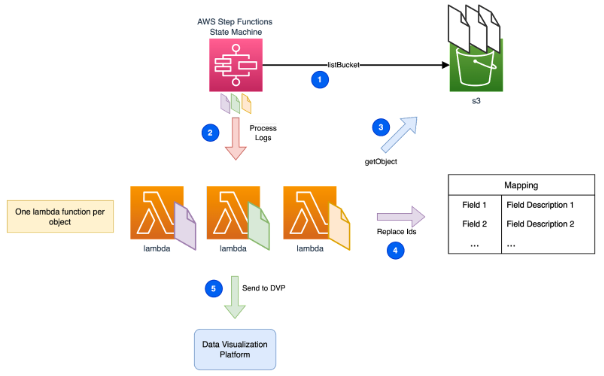
Find a Terraform module to deploy this scenario (simplified).
In conclusion, the solution presented offers a user-friendly approach that does not necessitate any prior expertise in Lambda, Python, or step functions. Its intuitive design ensures ease of use for individuals regardless of their technical background.


