
It seems that a new paradigm is coming. Facebook and Netflix have come up with different implementations for that idea. Some people are calling it Demand-Driven Architecture, but before I show you some solutions, let's go over some history to understand the problem. I will use the example that Netflix provides, but I think that most of us will find the patterns familiar.
Just for clarity, let's assume that we have an on-demand streaming service -- quite similar to Netflix :) -- that has three microservices. One contains the genres, another one the titles and the last one contains the ratings that different users give to those titles. As we're in 2015 we'll discard RPC as architectural style and we'll go with a RESTful design. Let's briefly enumerate the characteristics of a RESTful design:
- HTTP verbs have direct correspondence with CRUD verbs. One of the benefits is that clients can understand what is going on the server without digging into the implementation. For instance, we know that PUT is idempotent, so as there will not be any side effect, the client can call to that endpoint several times in a row without any issue.
- We use extensive HTTP caching. Through headers like Cache-Control or ETag, we leverage one of the most juicy features of HTTP: caching resources.
- HATEOAS for the win. Every single representation should have links to different representations so the clients can navigate through our backend like a graph.
REST limitations
Let's imagine that we send a GET to the genres endpoint. The response will include links to other GET requests like titles/1234 or ratings/6789. If we have the title "Titanic" in different genres (romance, drama and DiCaprioRules) you can see how the client is going to do at least two redundant requests. Apart from that the client is going to reshape the data whenever it comes back since it's likely that the client won't need every single field that those responses include. So, we have two problems with this design:
- High latency as we don't optimize calls.
- Large message sizes.
Patching REST with RPC
One way of overcoming these problems is customising our requests with query params. You can say to the server something like "give me only a couple of the fields that you expose on that representation"" or whatever arbitrary parameter. That means that you'll lose the caching that HTTP offers as now you'll have a ton of possible not-really-resources to cache.
Also you can create new abstractions ad-hoc that aggregate that for the client. In fact one of the benefits of CQRS is being able to create different views of your internal entities, so the demands of the client doesn't affect your domain modeling. That has a problem though: there is a big a coupling with the server. Our system has a massive amount of fragmentation as you can stream over Android, iOS, TVs and also, different versions of the same client device. Therefore there are going to be different needs and rhythms and the coordination between backend and clients is going to be really messy.
Also, CQRS is amazing in the fact that you could decide to model your system around different bounded contexts, i.e, different CQRS deployables. If your client needs a view that aggregate data from two CQRS units, you have the same problem.
Demand driven architecture to the rescue
This leads to the point of Demand Driven Architectures. Conceptually the backend is just a single entity and, since it's modeled using REST principles, it's defining what is the shape of the data. However, we're going to have tons of clients with different needs and all of them need to twist themselves in order to get the shape of the data that they want. Would it be great if clients could just send queries to the logical data unit called backend?
If we think in a relational database the concept is similar. We have different tables (rest endpoints, resources, backend services) and we have a query language that allows us to join and shape the data easily. Some of the optimizations of that query will be done by the platform that runs those queries.
Falcor and JSON Graph
Netflix has created a tool called Falcor that tries to solve this concrete problem. Clients won't talk with the backend services directly anymore, instead of they will send queries to a Falcor service that will do the routing, aggregations, projections and optimizations. This is an image from Falcor's official documentation.
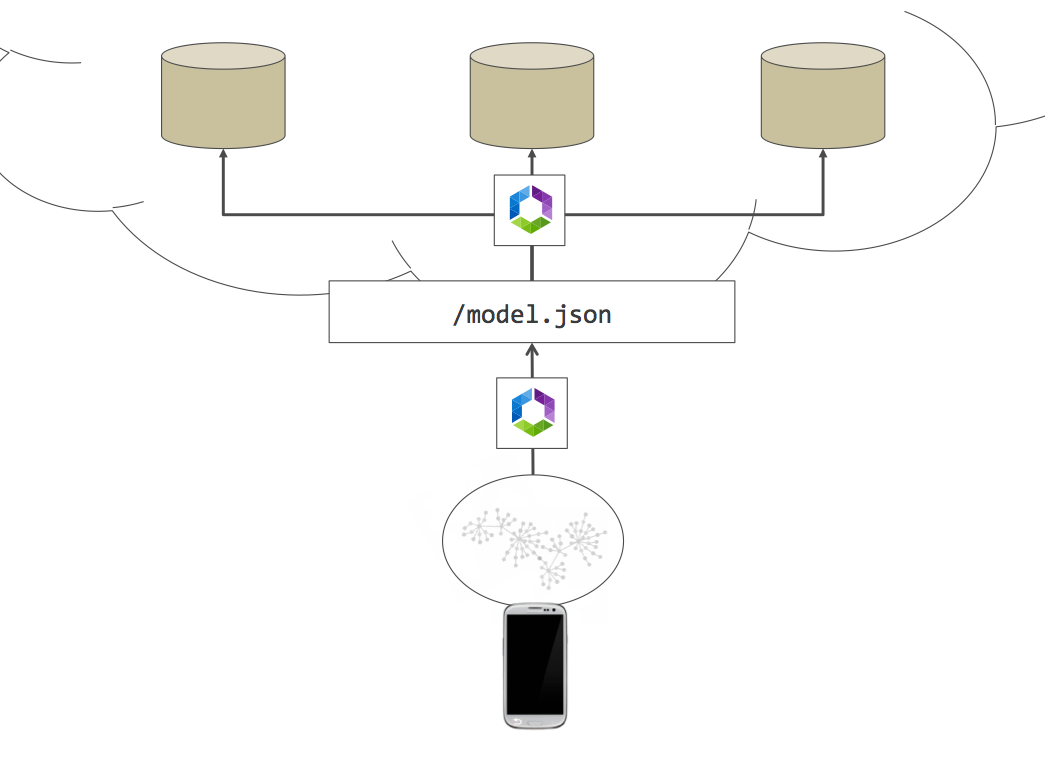
They based that platform on the idea of JSON Graph. Let me explain it briefly. JSON is in essence a tree structure. However, most of our data has relationships so it should be modeled like a graph. Using REST design programmers usually solve that problem through ids, but that makes our life really difficult (think about problems like cache invalidation). As they say:
JSON Graph is valid JSON and can be parsed by any JSON parser. However JSON Graph introduces new primitive types to JSON to allow JSON to be used to represent graph information in a simple and consistent way.
They borrow the idea from unix filesystem. That filesystem is a tree, but thanks to symlinks you can emulate the behaviour of a graph. That has massive implications in the way that Falcor optimises calls to backend services. Instead of keeping some values in a denormalised fashion, Falcor keeps references to that normalised value, so, if you ask for a value that has been already retrieved, Falcor will avoid that call. Also That makes cache invalidation much easier.
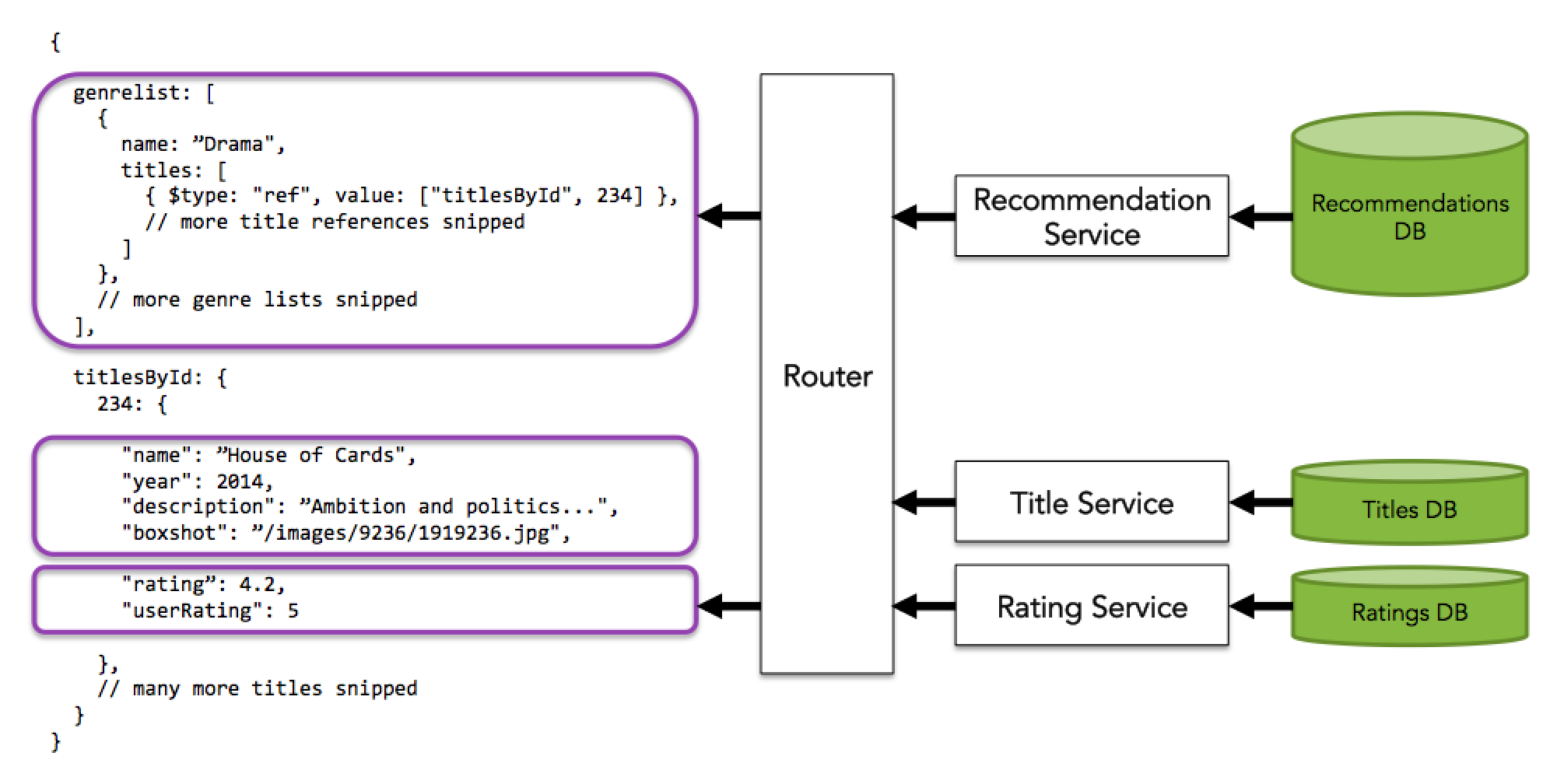
As you can see in the example, we don't store denormalised documents for titles inside of genres, but a reference through a titles map indexed by id. I can show you some code that I've been working on for a proof of concept. Falcor server side is currently only available on Node.js but there are plans to porting it into another platforms.
router.get('/model.json', falcorKoa.dataSourceRoute(new FalcorRouter([
{
route: "teamsById[{integers:teamIds}]['name', 'memberCount']",
get : function(pathSet) {
const teamIds = pathSet.teamIds;
const keys = pathSet[2];
return teamsService.getTeams()
.then(function(teams) {
var results = [];
teamIds.forEach(function(teamId) {
keys.forEach(function(key) {
var team = teams[teamId];
results.push({
path : ['team', teamId, key],
value: team[key]
});
});
});
return results;
});
}
}
])));
The client side would look like this:
const model = new falcor.Model({ source: new falcor.HttpDataSource('/model.json') });
model.get('teamsById['1234', '456'].name');
model.get('teamsById['789']['name', 'memberCount']');
IN CONCLUSION
There are no silver bullets in software and nobody is claiming than Falcor or GraphQL are going to solve every single problem with client/server integration. However, if you have an application with a lot of clients and your backend has a complex data model, it might be worth giving this new paradigm a try.