This morning, shortly after starting work I was sent a message about a problem with an application being deployed into our prod environment.

Now, I’m fairly new to kubernetes, but this seems like it should be a simple fix, I just need to replace the expired certificate with the new one and restart the service, right? But then, it’s never really as simple as that, is it? Well, it actually is almost as simple as that. I did make a wee mistake that I’ll get to later, lets get into checking that the cluster certificates actually have expired. First open a connection to the server(s) that your master nodes are running on, and run this command:
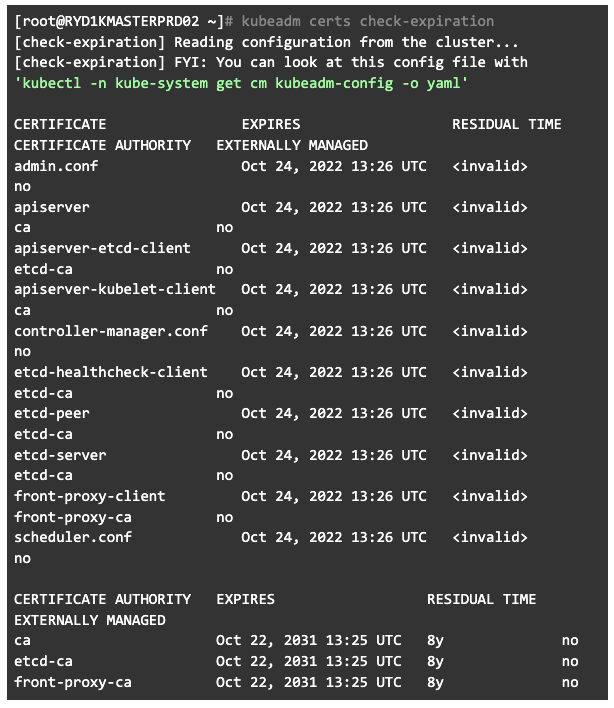
(FYI, I created these screenshots on 26th October) So as we can see, these certificates have expired and all need to be replaced. This can be done in a single command.

This will renew all of the above certificates for you on the node you run it from. You’ll need to update your admin kube config to refer to the new certificates, you can copy them from /etc/kubernetes/admin.conf
You now also need to copy these certificates to all other master nodes. This was the mistake I made, I had assumed that kubeadm would magically replicate the certificates and I wouldn’t have to, and to my surprise, I was now intermittently getting the expired certificate error. It was only afterwards I realised that the other master nodes also needed the certificates replacing , and yes, it seems obvious to me in hindsight, but I’ve learned something new so it’s a success, in my book.
Having copied the certificates from the first master to the others, you’ll notice that none of your kube services are using them yet. They have to be restarted before they can pick them up. The following commands will do that for you.
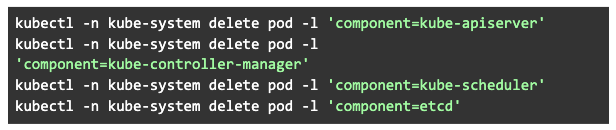
What these commands do is delete the pods in the kube-system namespace.
Kubernetes has a wonderful ability to self-heal, so when you delete pods, that the cluster expects to be running, the cluster will automatically recreate them, with the only difference being that the newly recreated pods will have the new certificates on them, instead of the old ones.
Once you’ve done that, your cluster should be back to normal, operating as expected.

