
- By María Dueñas
- ·
- Posted 21 Mar 2024
Advanced TDD learning path
If you have a lot of experience implementing TDD, your learning plan should focus on deepening your understanding of advanced principles, exploring..

A long time ago, I met a development team which was working under big pressure by the quality team. Personally, I don’t like this kind of differences between development and quality teams, because it leads to development teams not feeling responsible for quality and to a confrontational relationship. They should be working collaboratively towards a unified goal of delivering a quality product.
One of the requirements was to have more than 85% of code coverage to ensure code quality. The result was perverse: development team wrote tests without assertions; they only invoked methods with different arguments to reach the desired percentage. It’s clear that they didn’t follow TDD.
Code coverage only gives us information about the percentage of code lines which are executed during tests.
Let’s see a way to verify that our current tests provide us with a safety net when we make changes to production code.
If we change the production code - replacing < with >=, swapping + with - or we return a different value in a given method - test battery should detect that change. In order words, tests should fail.
There are tools to make changes in production code automatically and to run tests in order to check if those changes are detected. It is usually referred to as follow:
So, we should aim at killing every mutation with tests.
When I heard about it I thought about that game I played when I was just a teenager: Super Pang.
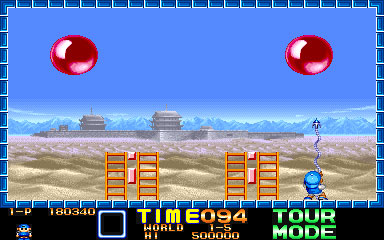
And I imagined the following situation: balls are mutations of our production code and the child tries to break those balls with tests rays. Tests must be good enough to detect the balls and to break them.
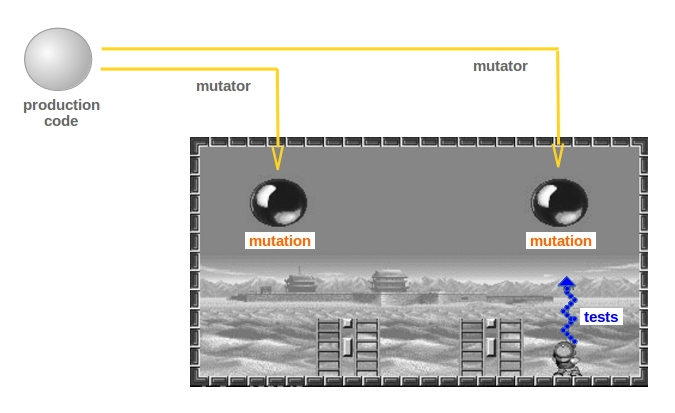
It’s called mutation testing and it's a good way to make sure that you have a good safety net with your current tests to refactor production code or to add new features. It is as if you test your tests in order to get more information about their suitability.
Let’s see some examples with PIT and a simple Java project with problematic code.
A boundary value could be forgotten when writing tests (even following TDD). For example, this piece of production code:
status arg3 = ((from.getParam1() < from.getParam2())? BLACK: WHITE);
If we don’t have a test which considers the same value for param1 and param2, a mutation will survive when applying Conditional Boundary Mutator:
org.pitest.mutationtest.engine.gregor.mutators.ConditionalsBoundaryMutator
Generated 1 Killed 0 (0%)
KILLED 0 SURVIVED 1 TIMED_OUT 0 NON_VIABLE 0
MEMORY_ERROR 0 NOT_STARTED 0 STARTED 0 RUN_ERROR 0
NO_COVERAGE 0
PIT report shows the affected line.

I try to avoid having logic in production code which is only used from test code.
It’s common to find equals and hashCode methods in Java which are only used in verifications or assertions. It’s easy to generate the code of these methods automatically with an IDE such as IntelliJ IDEA, but at the same time, it’s easy to have outdated code if we don’t remember to regenerate them when changing the involved class (or we don’t receive an alert about this fact).
For example, a property is added to a class without updating equals and hashCode methods, so PIT statistics results in:
Generated 15 mutations Killed 6 (40%)
Ran 24 tests (1.6 tests per mutation)
And PIT report alerts on equals and hashCode methods.
If these methods are only used from test code, we can replace them with EqualsBuilder.reflectionEquals from Apache Commons Lang:
assertTrue(reflectionEquals(actualObject, expectedObject));
In that case, we can succeed in killing every mutation:
Generated 5 mutations Killed 5 (100%)
Ran 7 tests (1.4 tests per mutation)
Another option could be to use field by field comparisons from AssertJ. It's useful if the object under comparison has other custom objects as properties, so comparators for types can be added by usingComparatorForType.
Others prefer Lombok to make equals and hashCode methods available, but maybe it's not necessary if you only need to compare objects.
Regarding verification, refEq is available from Mockito.
Take a look at Code quality cannot be measured by Sandro Mancuso.
My special thanks go to Halima Koundi, my very good colleague, for her help in this post.

