In the first part of his series on Modernising the Public Sector, Carlo looked at the risks of failing to modernise legacy systems which range from loss of data and outages to failures in critical sectors, such as hospitals or transportation.
The migration of legacy systems requires a well-defined strategy, and the experience of a specialised partner is essential to avoiding failure.
In this second part Carlo addresses the steps required to decouple applications sharing a common database schema
As a possible scenario: Let’s see a practical example of a database-sharing scenario:
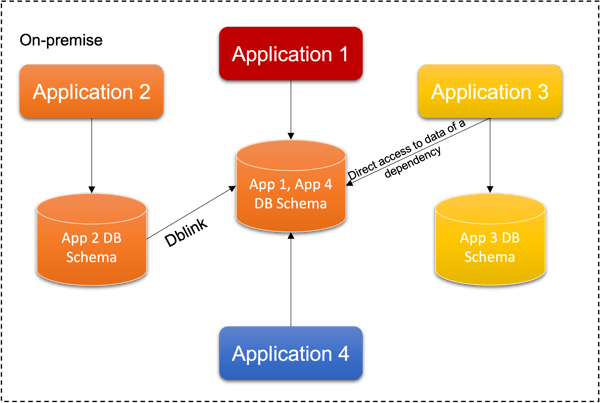 This is the situation presented in this scenario:
This is the situation presented in this scenario:
- Applications 1 and 4 share the same schema, with some tables in common (see picture 1)
- Application 3 accesses directly the application 1 and 4 schema
- Application 2 access to the application 1 and 4 schema through a dblink
Let’s suppose that the DB licence is outdated and can’t be renewed.
The need
Application 1 must be evolved and moved to the cloud as per GDS recommendations.
The motivation for the selection of a specific application to be moved to the cloud instead of one another is out of the scope of this article, but these can be some reasons:
- Application 1 is the most urgent to move to the cloud because needs to scale out in the next months exceeding the on-premise data centre capacity
- There is no budget or time to move all the applications into the cloud at the same time
The motivation for an urgent decoupling of application 1 from other applications, independently from the shift to the cloud, could be this: schema sharing is blocking strategic improvements of application 1.
The solution, step 1: separating the database schema fully shared between two applications
The first part of the job consists in separating the shared schema between applications 1 and 4.
Starting point: a single schema containing all the database objects from applications 1 and 4.
Objective: two separated schemas, each of them with the database objects of one of the two applications, each of them with a different database user.
The solution consists of these main steps:
- Assessment of the applications that shares the database
- Decoupling the applications
The schema in common to applications 1 and 4 must be split: one application will use the new schema, while the other application will continue to use the old schema. A new database user will be created for the new schema.
Which database objects, can we move from the original schema to the new one, being sure to not affect the application's behaviour? We are dealing with legacy applications, so no tests are available.
The prerequisite for every intervention like the one in this example is an assessment of the applications to understand use cases and main flows, and then an implementation of an exhaustive suite of tests.
The identification, design and build of the test is outside of this article, however, Sam Davies offers great insights and further practice suggestions in his excellent article; How to test legacy software (that was not designed to be tested) when modernising.
Assessment
In the assessment phase, a thorough analysis of all the applications that share the same db must be done, answering these questions:
- Which applications access to the DB directly or through dblinks?
- Every application has its own DB user or DB users and related permissions are shared between applications?
- Which applications access in read-only mode and which ones access in read/write mode? To which tables?
- Which queries are executed by the applications? Which data are needed by satellite applications? Satellite applications are the ones that have a dependency on the data of the database, but it is not their main database. Applications 2 and 3 are satellites, in the proposed scenario.
All questions must be answered to have a map of the appilcations-data relations and to plan the automatic test suite that must be implemented to avoid regression errors.
The assessment could evidence some actions that must be taken before moving to the next phase. For example, if two or more applications share the same DB user (and so the same permissions), further db users must be created and assigned to these applications; the newly created users must be granted with only the minimum needed rights. This is a sub-project by itself: the grant updates must be tested, deployed in production, monitored, corrected in a sequence of iterations. If there is no test environment, then one must be implemented.
Decoupling two applications that share the same database schema
The first step is to implement automated tests that cover the main use cases identified during the assessment. It is not necessary to cover everything, and for further details, you can read the document mentioned before; How to test legacy software (that was not designed to be tested) when modernising.
The “Database per service” pattern has to be applied to decouple the applications.
When a reliable suite of tests is available for both applications 1 and 4 it's time for refactoring: database objects can be separated between the old and the new schema (let's suppose to move the application 1 object in the new schema), application 1 must be reconfigured to connect to the new schema, and the automated tests must be run on both applications to identify failures. If a failure happens, it means that an object is shared and a strategy for the conflict must be applied.
If there is no confidence about which tables are related to one application rather than another, then an analysis of the code must be done. The automated tests can also help in this stage: they can be run as many times are needed to understand if the table was moved correctly, has to be replaced in the original schema or if there is a conflict. The same applies to other database objects.
When moving a database object from the original schema to the new one some problems can happen:
- A table is shared between the two applications. In this case, it must be decided to which domain belong the data in the table, move (or leaving) the table in the belonging schema, implement a web API that accesses the data (as part of the belonging application or, if possible, as a micro-service accessed by both applications, with a dedicated schema) and modify the client application to access this data through the web API.
- A table is composed of a set of columns useful only to application 1, a set useful only to application 2 and a set useful to both. The first step here is to split the table in three: the original one will keep the data (columns) common to both applications, and two newly created tables will keep the data (columns) useful only to a single application. The primary keys are replicated in all three tables. After this step, the newly created table with data useful only to application 1 will be moved into the new schema, and the original table will be managed as illustrated in the previous point
- A table to be moved in the new schema has a foreign key that references another table in the original schema. There is no problem if the referenced table has also to be moved in the new schema: both tables will be placed in the new schema and the foreign key will not be a problem. Otherwise, the two tables must be separated and the relationship between them will be handled in another way. It is needed to avoid database links because they will couple the two schemas, so the solution must be implemented at the application level with an API, as explained above. All kinds of relations (1-to-1, 1-to-many, many-to-many) can be handled in this way, but before acting it is needed to understand to which domain (the one of application 1 or application 2) belong the relation. For example, let's suppose that application 1 handles products, while application 2 handles carts in a hypothetical e-commerce scenario: products have a relation of many-to-many with the carts because more than one cart can include the same product. The many-to-many relation, in this case, belongs to the cart domain, because describes the cart content: in this case, the many-to-many table will live in the cart service schema, and will contain references to product IDs. The reference to the product IDs is made by storing the ID that the catalogue application assigns to the products, and cannot be defined as a foreign key at the schema level because the product table will live in another schema. The next step is to understand which application will use the information from the other one and to implement at the API level the code for exposing and/or consuming the data from services.
- If the problem is generated on triggers and stored procedures, then probably the latter is dependent on tables belonging to both applications, and one or more of these tables are moved in the new schema. At first, the domain of the procedure must be analysed: to which application belong the logic implemented in the procedure? The answer to this question will help to understand where to re-implement the procedure. Secondly, may be worth understanding if all the logic implemented in the stored procedure is still meaningful and, if not, trying to remove it (after the implementation of the needed automated tests). If the removed logic eliminates the procedure dependencies with the tables of application 1 then the problem is solved. In case of less luck, then the stored procedure and triggers must be reimplemented at the application level in both applications, interfacing together to execute the original stored procedures behaviour.
The following schema represents the improved scenario, with applications 1 and 4 separated, each one with its own schema. Application 1 has a new component called “Application 1 API”: it will be used by application 4 to access the data that were in the shared database.
We can suppose that Application 4 needs to access data managed by Application 1 and not vice-versa. This is because, in the following steps, we need an application free of dependencies to be moved to the cloud.
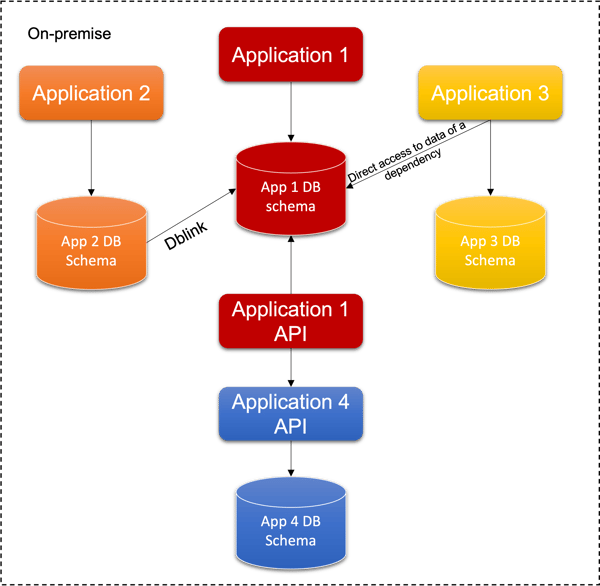
The solution, step 2: decoupling the application from the other ones that relies on the same database
The goal is the re-platforming of the application stack, with “Application 1” moved to a cloud virtual machine and the DB schema moved to a cloud managed database service (e.g.: AWS RDS, AWS Aurora, Azure SQL Database, Azure Database for PostgreSQL).
In our new eBook; Crafting a Cloud Migration and Modernisation Strategy for the Public Sector we explore other, better solutions for “Application 1” (e.g.: to be rewritten for containers or for serverless).
It is also worth exploring our other blog articles on software modernisation and cloud migration.
The problem with the situation presented in the previous picture is the fact that more than one application accesses the database at the same time, in read and/or write mode.
The solution consists of these main steps:
- Assessment of the applications (already done in the phase “separating the database schema fully shared between two applications”)
- Decoupling the applications
- Move “Application 1” and “Application 1 DB” to the cloud.
The real solution has many more steps that are avoided here to not burden the example of the very specific problem of shared databases.
Again, the “Database per service” pattern has to be applied to decouple the applications. “Application 1 DB” must be accessed only by “Application 1”, and the other applications can’t have direct access.
Other applications can interact with “Application 1” data in different ways, for example;
- Through APIs that must be added to (or built by side of) “Application 1”
- Through a sync mechanism that replicates the needed data from “Application DB 1” in other databases (e.g.: data warehouse) accessible by other applications.
In the paragraph "Decoupling two applications that share the same database schema" a list of possible database coupling mechanisms was tackled, offering different solutions to reach the decoupling.
The same problems and solutions must be applied to solve the direct access from Application 3 to the data of Application 1 and the dblink from Application 2 schema to Application 1 schema.
In this case, the database schema of Application 1 is not fully shared with applications 1 and 3 because these applications have their own schemas.
Also in this case; assessing, documenting, implementing automated tests and finding the right strategy to act must be done for every object that applications 2 and 3 use in the Application 1 schema, exactly as explained before.
Here down there is a diagram representing the applications decoupled by the API service created in the previous step. The solution represented consists of newly created APIs functions in the “Application 1 API component”, leaving untouched the “Application 1” business logic. Application 2 and 3 must be modified to make http API calls to the “Application 1 API” component.
The API component can be split in a set of micro-services, but this is beyond the scope of this document.
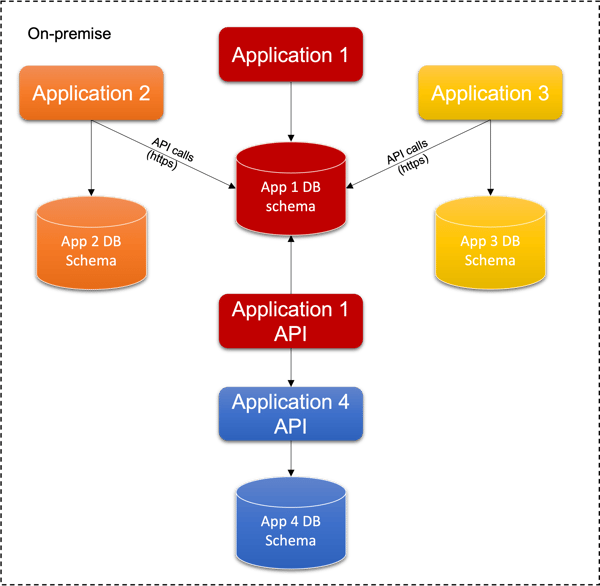
During this phase, automated tests must be executed in order to avoid regression errors. The tests must be implemented following the information collected during the assessment phase.
Moving the application to the cloud
After the application decoupling the stack “Application 1”, “Application 1 DB” and “Application 1 API” can be moved to the cloud. The API component can be exposed to other applications through the Internet or a VPN. The APIs must be implemented and deployed with all the security constraints required (e.g.: HTTPS, VPN, authentication/authorization), and the applications still on-premises must be configured and allowed to contact the “application 1 API” component.
The schema App 1 DB could be migrated to a db server in the cloud, possibly a managed one; if needed, a conversion between different DB engines objects (e.g.: from a commercial database server to an open source one) must be done.
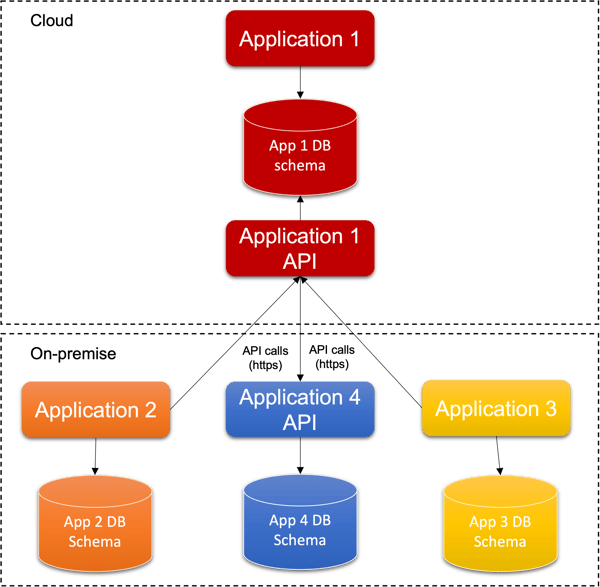
Conclusions
The public sector is facing the challenge of legacy application modernization, and often this challenge is made harder by practices like RDBMS-centric infrastructures.
To get rid of the burden of legacy infrastructure it is necessary to define a strategy and apply an iterative method. An experienced partner could help.
Why not download a copy of our new eBook: Crafting a Cloud Migration and Modernisation Strategy for the Public Sector which focuses on cloud migration and modernisation strategies in the Public Sector. Download your copy here.


/ebook%20modernizaci%C3%B3n%20+%20IA_guia%20CTOs/IA_modernisacion_form_bg.png?width=528&height=528&name=IA_modernisacion_form_bg.png)
