
- By María Dueñas
- ·
- Posted 21 Mar 2024
Advanced TDD learning path
If you have a lot of experience implementing TDD, your learning plan should focus on deepening your understanding of advanced principles, exploring..
Welcome pythonistas!
During the last session we talked about testing in python. We went through the topic of mocking relatively fast so I would like to express here some methods and ideas that we left behind. These ideas will be:
- Monkey patching
- Mocking and patching in pytest
The examples here are more or less self explanatory but you could find all the examples in the branch `blog1` of the repository dedicated to testing in Python. I encourage you to test the examples and open a discussion on topics, doubts or aspects that could be relevant for you.
As you might know monkey patching is the action of modifying a class or module during runtime. One example of general use of monkey patching could be:



You might notice that we patched the all builtin function (not recommended to do this, just for illustrative reasons). This behaviour could be useful many times but one should be really cautious with it because it will leave behind definitions in a running environment that are not obvious by the written code itself.
Imagine an infinite loop in a server where we have monkey patched a key functionality and we are always returning the same... But it is exactly that behaviour that is likely that we want when testing using a package on which we do not have control or we do not have the infrastructure to access.
Pytest is aware of this situation and provides a builtin fixture to work with monkey patching during your tests. This functionality takes care of patching and when the test finishes, it returns the patch module to its original state, to be reused (if that is needed) without any changes or patch. Let see one example of this fixture.
Imagine we have a class that models the invoices in our company. This entity must have an ID and other kinds of data. But for our kind of tests we need to ensure and work with the same ID for the sake of simplicity. While for other batches of tests we do not have that need. In this case look at the code below:
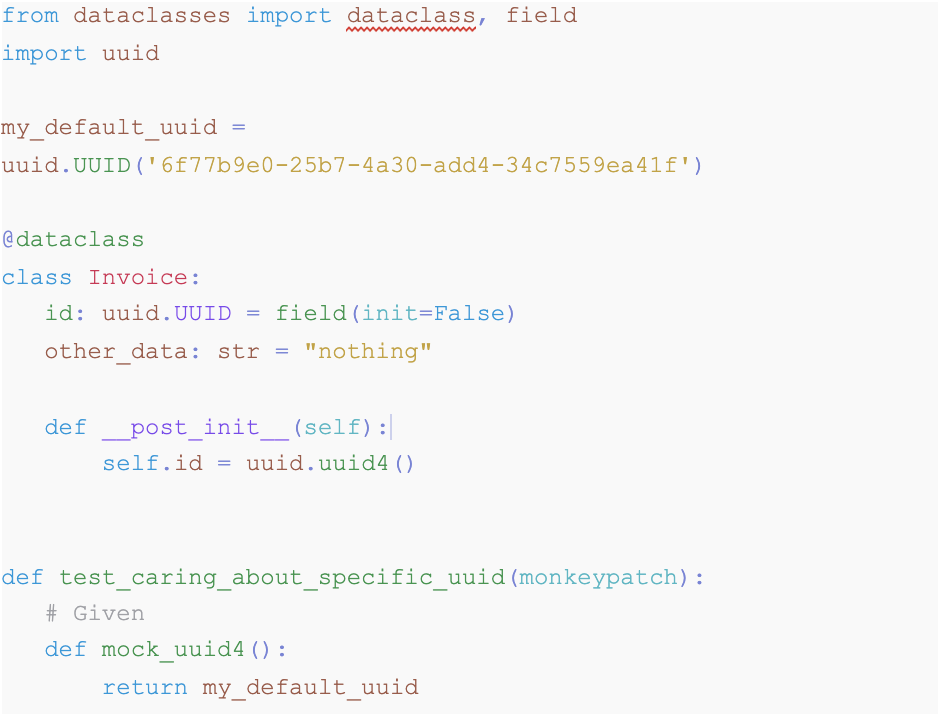

One can observe here that within the scope of the test that is using `monkeypatch` we are replacing the `uuid4` function by our own definition that always returns the same uuid. The good thing is that we do not need to teardown (undo) this patching at the end because the fixture takes care of it.
Another usage of `monkeypatch` could be for replacing an environmental variable. As shown in the example below it could be relatively common to use an environmental variable to know in which environment is running our code. Based on that variable some features could be active, so if at the beginning of testing we set it to the `test` environment. (Remember to set your `ENV` environment to `pro` in your local environment or at your `.env` file.)



As mentioned in the last session when we are in the need of a double that provides extra behaviour (like the times that it was invoked, or whether it was invoked successfully) one should look towards the `Mocking` library.
The magic behind `mocking` is the `MagicMock` (bazinga!). Indeed the base of the library is `Mock` class but the magic subclass already implement support (mock capacity) for all te *magic* or *dunder* methods (yes, those with double underscore as prefix and suffix). Strictly speaking one could use these classes without being in a testing environment (framework). Let's check out in such a non testing environment the capabilities of mocking.


You might notice that:
We could increase the behaviour of the mocking library from a simple mock to a stub by modifying the example above.


So we can see the utility of having this tool for testing, but there are two problems with `MagicMock`:
So the last main feature of this library is the `patch` function that provides a solution to the previous issues. It is used as a decorator or as a context manager and to see it in action we will need a more complex example.
Imagine we have a scaffolding like:

Imagine that in the patch_example.py we want to mock the Invoice class as we did it before. Now the situation is more complex because we are not defining the class directly in the same file as the code that was mocking.
In these situations patch will turn really handy. The code for having something similar using patching will be like:


First thing to notice is the way of using the first (and mandatory) parameter of patch (the target). This should be the path to the place in the code where we want to replace the mock, or as Lisa Roach mentioned in a nice talk Patch where the object is used. It is not where the object to be mocked is defined in our code....this is key, so take your time to digest this way of working. In our example Invoice is defined at the domain but we want to replace `Invoice` by the mock in the context/scope of the app.py within the application.
So it is the path to application.app what we have to use to mock there.
As you might also notice the patch is only applied within the context and we do not have to handle the unpatching process. These are really convenient features of the library. Once outside of our context manager calling the same function will run without using the mocked object.
The situation where we have a complex organization within the namespace is expected when we have to test. At least we will always split the code under test and the code of the tests in two different files, but for instance I have the preference of putting them in separate folders and the scaffolding and name-spacing within the src usually will be complex. In addition it is likely that each test case would need a specific patch. So it is convenient that the library takes care of unpatching once out of the scope.
So instead of using the mocking library like we have been doing (outside any test framework), let's use it in its more natural environment: within pytests.

In this case we used the patch as a decorator instead of a context manager. The reason is that we are just mocking once and we do not have the need of unpatching within the context of the test function. Usually this is the common situation and that is why the decorator version is more widespread.
Let's imagine a more complex situation in which we have a repository that due to the pace of the project is not yet implemented but we know that there will be a method `write_invoice` that will be used every time that we update the invoice backlog. So the repository.py file may look like:
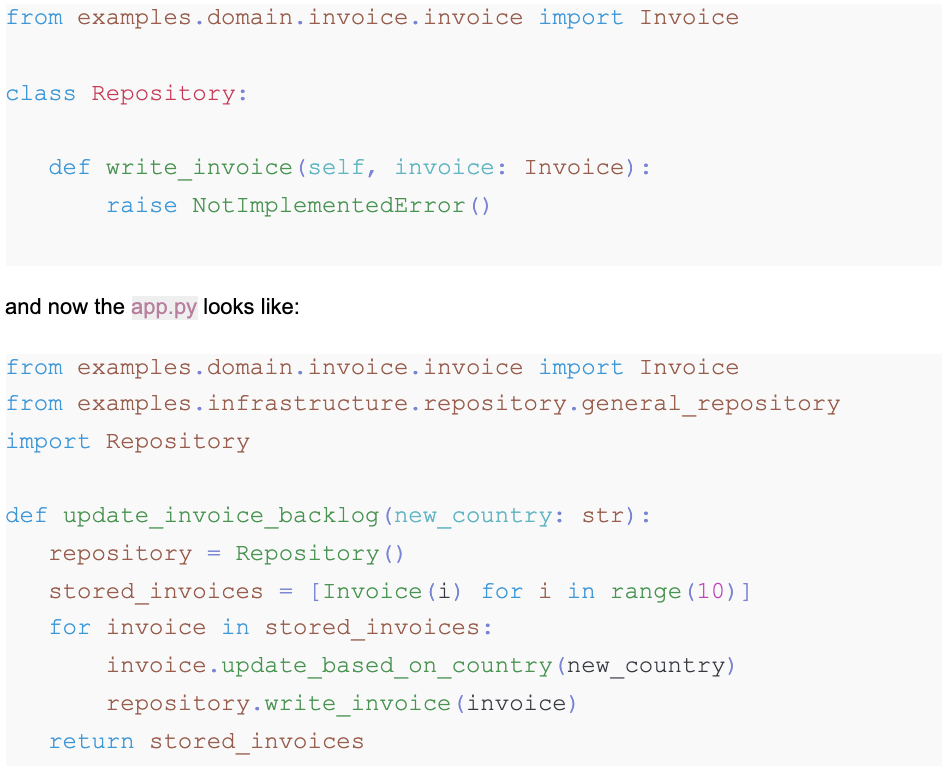
So we want to store our entities and still we want to run the test that we studied before. In order to do this we need to add a new and more meaningful patch (mock) that will simulate the existence of this repository.
When we say more meaningful what we mean is that usually are the repository and other gates into our domain the kind of objects that will make use of infrastructure or expensive computations that will not be acceptable in unitary tests. To adapt to this situation we need to modify a bit the previous tests by doing:

We are using two patches but notice that the order of the parameters that they take in the test function is the inverse of the order of the decorators. We expect to have just one call to the repository and the same amount of calls to the write method. It is important to highlight that by doing this we are able to test the functionality of our domain/application independently of the specific implementation of the repository (the persistence could be then in a database, in drive, in memory, etc.). By abstracting this way we are more free to focus on our own dependencies.
We have seen that while testing there are situations in which we can not afford to work with the current implementation of the code. Mainly this is because the cost of adapting the code to a testing environment will make that code really difficult to maintain and to read. So monkey patching and mocking provide the possibility of replacing elements in our code by elements that will not have any dependency and that hence will not complain.
We have seen that using these tools we can also extend some behaviour or replace it, to cover all the possible corner cases that we can think about.
Despite these packages being used mainly during testing, it is a healthy exercise to test them just running in a regular script to avoid any distraction from the test framework. This is what we have done; but at the end we have seen their utility in the most common environment a test framework.
In the next article we will treat more topics related with testing. Until then, remember to be brave and bold! and remember:
We have more events scheduled about Python.
Take a look at our events page and join us!

