The technology landscape is constantly changing and as a result, we can often see that some applications don’t stand the test of time. To counter this problem, we can choose to extend, rebuild and re-architect the existing applications.
Often, I have seen that rebuilding the legacy system is the proposed solution. While this is an engineer’s dream solution, it is highly impractical and costly in terms of time and money.
One thing to note is that containers are no longer the bleeding edge of technology anymore and their value has already been recognised. Containerisation can help to support the modernisation through modernisation of underlying technology.
In this article, I am going to explore the refactoring / re-architecting approach which helps to transition us into an evolutionary solution that can support both present and future needs.
To start with, let's look at the advantages and challenges of containers, let’s briefly look at the problems they solve and those they do not.
Advantages
- Containers allow for more portability.
- Containers can provide the foundation for microservices architecture. I must stress that while it is easy to think of containerised applications as microservices they are not synonymous with microservices.
- Containers solve the “it works on my machine” problem. It can function on a developer's system as well as a production-grade runtime with minimal to no modification.
- Containers can encapsulate all dependencies an application needs in a neat and tidy package.
- Allows developers to collaborate with platform engineers by writing IAC files such as a Dockerfile.
- Containers allow us to test changes faster without worrying about the rest of the infrastructure.
- Automating deployments becomes easier.
- Horizontal scaling is much easier.
- It is quicker to deploy
- Allows for better view and control of the security of the application package
Challenges
- There are changes needed at an operational level to effectively leverage containerisation.
- Containers cannot operate at bare-metal speeds.
- Not possible to run a Linux container on Windows or vice-versa
- Cannot run graphical applications such as desktop apps.
Should all apps be containerised?
Not all apps are right for the cloud and not all apps are suitable candidates for containerisation. Examples of poor candidates are:
- Old applications, built using proprietary languages or technologies. Think of apps that rely on a special hardware feature, such as mainframes. It might be more economical to rebuild these in the cloud.
- Apps that will require a complete rework. Converting your legacy app to a microservices infrastructure requires a complete rethink of the infrastructure. Not every IT department will have the budget, resources, or time to do that
Without further ado, let’s look at what we need to evaluate in order to containerise existing applications.
How do I get started?
Let’s imagine that the application you’d like to run in containers is a legacy monolithic application. This application has some background processes in the form of Linux cron jobs and it uses a single relational database as a back-end. The list below is by no means exhaustive, but it should give you enough to think about when planning your changes.
Plan for Containers
Firstly, there needs to be a strategy that builds on the needs of your applications. There are several possible solutions for deploying a legacy application in a container:
- Rewrite and redesign your legacy application.
- Run an existing monolithic application within a single container.
- Refactor your application to take advantage of the newly distributed architecture.
Regardless of which method you chose, the key thing is to decide whether the application is a suitable candidate for containerisation.
When coming up with the plan, keep in mind future evolution, as you look at the architecture, performance and security.
We can also look at the application stack diagram. If one doesn't exist, take the time to create it. The diagram helps you identify shared technologies / libraries amongst the applications you have selected for containerisation, as well as being of value in the future.
If you have numerous applications that share similar libraries, language version, web server and OS, then these can be combined into a base image that each application can use as a starting point.
Take the time to look through system configurations or constraints.
For example, I received an error on my newly containerised web application. This happened when I was trying to upload a larger file than allowed in the web-server configuration.
It helps to look at language and environment configurations.
Identifying dependencies
Before you set to work on any refactoring, it is imperative to analyse your application and operating system’s dependencies. For example, you may need some OS libraries e.g. libzip before your language can provide that as part of standard lib.
If you don't have the luxury of having these package management files, you can always get your hands dirty and 'grep' the codebase to find any includes or imports which may reveal third-party libraries used.
Environment variables
Search for all places where environment variables are being used. I've seen these being used for injecting various pieces of information such as API keys, endpoints, paths or application environment.
Credentials and API keys can be better moved to a secure secrets management solution that integrates with your chosen container runtime.
Refactoring
Not all applications are built, from the outset, with a suitable set of options for containers. In these cases, you will need to refactor parts of the application. Common things to look at are configurations; such as settings per environment.
Also bear in mind that any classes that write data to local OS paths will need to be changed to a more distributed storage solution.
Build in acceptance tests, if there weren't any before. This will ensure that as you start to introduce changes, it functions correctly.
If you’d like to consider using the application in your current environment while you perform refactoring, you may be able to leverage feature flags.
This will give you some flexibility and safety.
Base Images
Imagine that you built your application based on a docker image you found somewhere. It had all the features you needed. A security exploit has led your application to stop working after you created it, based on this image.
Another example would be when your chosen base image is no longer available. And when you release your application next time, the build process seems to be broken.
To avoid such a mess, a wise place to start is to use official language images where possible and the closest matching version of Linux (or other OS).
For example, if you have a PHP 7.2 application that runs on Ubuntu 21.04 LTS, it would be ok to use a Debian bullseye base image.
Potential Pitfalls
You’ve got some idea about the kinds of challenges you can face. However, let’s look at some additional factors that can become roadblocks if not well thought out in your planning.
Data Storage Paths
It is imperative to evaluate your application to see where your application stores data. This is important because of the bindings to various OS specific paths. Let’s see two use-cases:
- Your application maintains file-based web sessions in some temporary storage. This may not appear to be a problem, especially when you’re only running one instance of the application. The storage size may not be a problem either, but will become an issue when the application starts to scale and has multiple instances running and your visitors can easily land in containers that are not having their web session stored.
- If the application serves static content that has been uploaded by users, we’d have to move the uploads to shared storage or migrate to object-based storage. So when you scale horizontally, you’re reading from and writing to a single place.
In these two scenarios, the common element is the need to figure out how we are going to have to architect data. This may lead to more tasks around migrating data to a shared storage.
SSL Termination
As SSL/TLS is used virtually everywhere, it is critical to figure this one out when you’re further along the process. This may not be a big problem initially, especially when there is only one instance of a container running.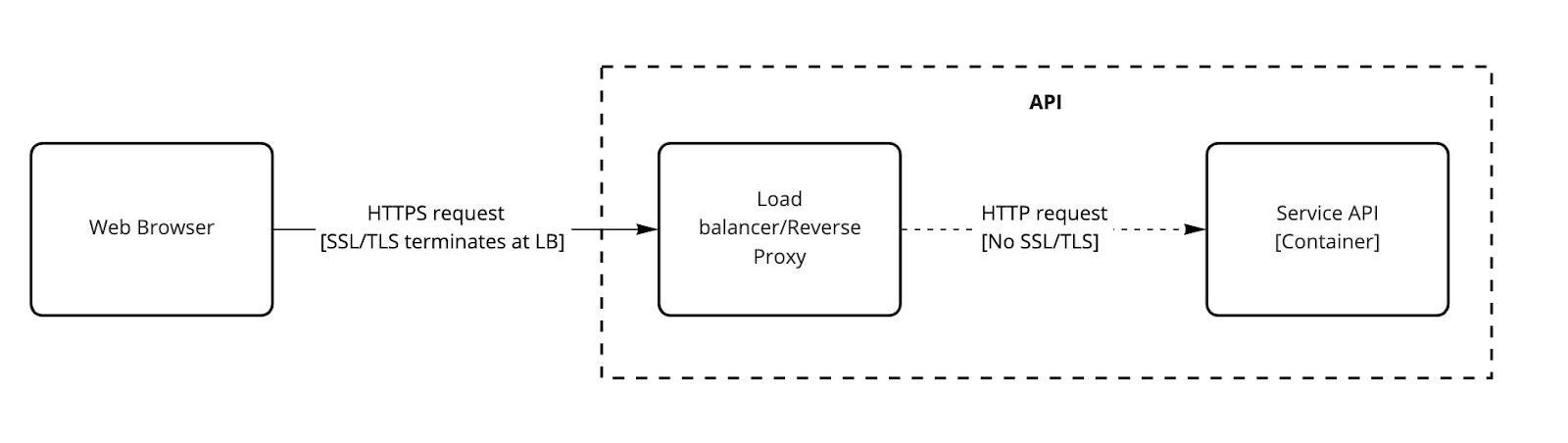
Considering the scenario in the diagram above, this is quite a typical setup in a containerised environment where your SSL/TLS terminates at the boundary (e.g. a load balancer) and then the traffic moves inside the trusted internal network but is unencrypted.
This now becomes a problem because if the application sets secure cookies which it should, they will not be transmitted to the browser because it comes over HTTP.
Cron Jobs
Containers should do one thing very well. So, when we look at the various tasks a typical application needs to perform in the background, cron jobs are very handy. They focus on one thing, but, to overload them into a container e.g. That is also a web server, is not what should happen.
We should only execute one process per container. This is because if we don't, the process that forked and is running in the background is not monitored and may stop without us knowing.
Let’s compare a few approaches.
Using the host machine’s crontab
This is not a high-scaling option, however, by utilising the host machine’s crontab, you can create scheduled tasks. Since cron job allows you to execute commands, you can use the container engine as you would a command line. This is done by using the same container as your web application but overriding the ENTRYPOINT command.

In the above example, your container will be recreated every 10 minutes and then removed after execution.
There are some pros and cons here e.g. You won’t have to worry about restarting docker containers. You won’t have to manage the logging, thus removing noise from logging. However, it’s not recommended to use a host’s resources as the background tasks can be quite hefty e.g. Report generation. This may also not be an option if your target runtime is a serverless environment where you don’t have access to the underlying host.
Using cron embedded in your containers
This is ideal for simple services as it gives us portability by packaging the crontab files directly into your container services.
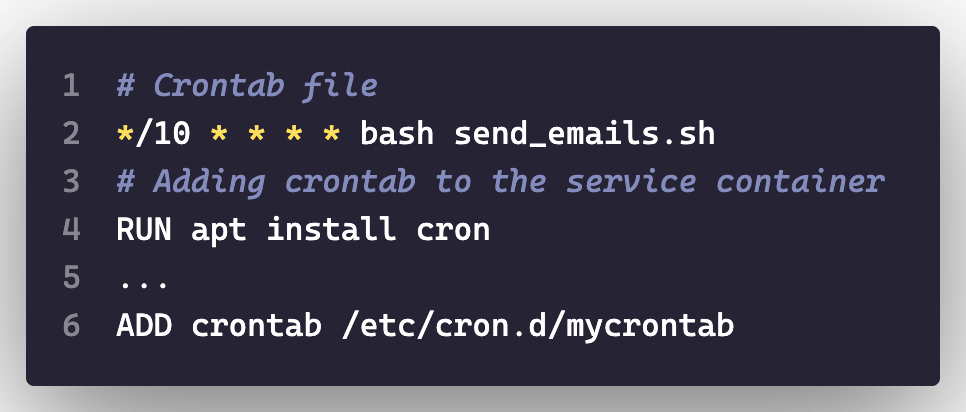
We can scale our application more easily this way since it is no longer dependent on the host machine. One caveat here is that scaling the number of containers can have serious implications if your background job does not deal with concurrent processing.
Furthermore, we deviate away from the doing one thing well principle
Separating cron from application service
For this approach, your application’s image should be the basis for both containers. Both containers will need access to the service’s volume and network. The only difference will be the foreground process for the container.

In this example, we use the same application image, but override the ENTRYPOINT command. At this point, task scheduling can be done in accordance with your target runtime.
File permissions
This problem is twofold. On the one hand, there are files created within containers and their permissions. On the other hand, file permissions are too open or permissive when you’re building the container images in the first place.
File permissions and ownership get copied from the host machine’s file system while building images.
Therefore, be mindful when building them in environments that implement the least privilege principle on the filesystem. Most CI servers will have restricted permissions.
So when you COPY or ADD files in a Dockerfile, you can specify the following:

Do not use the default root user as it can cause permission problems, and it also poses security risks.
The most effective way to prevent privilege-escalation attacks from within a container is to configure your container’s applications to run as unprivileged users.
Secrets
Extract any secrets, e.g. API Keys from the secrets management solution offered by your target runtime. Initially, you may not need a secret management solution, so moving these to environment variables would allow you to get on with the job at hand.
Image Optimisation
An obsession, I’ve observed, is trying to keep the size of your container images as small as possible. For example, your current application in Debian amounts to 500MB whereas the same application packaged up with Alpine Linux is 50MB.
I feel that pursuing this obsession can be a pitfall as not everyone on your team may be familiar with Alpine instead of Debian. Furthermore, there can often be differences between libraries deemed essential for the functionality of your application. However, having said all this, containers do allow you to experiment with these kinds of things in a much safer way. This should not be the goal in the beginning, but could be something that is done once you’ve become used to over time.
Horizontal Scaling
While this is the great benefit of containerisation, it also brings potential challenges. For example, data consistency and task coordination can be challenging across multiple instances. As a result, costs may be higher, and more code may be required to make that coordination happen. Furthermore, underlying servers may still encounter hardware limit issues if host machines are not specced accordingly.
Logging
The preferred practice for containers is to write them to the standard output stream so this will likely be different from trying to write logs to a specific file in the OS. This will enable you to see a combined view of various services, although you'll want to differentiate between logs from different services. A centralised logging solution would be needed to help with aggregation of various logs when you scale. As a result of this, there may be a need for a possible refactor of your logging driver’s configuration.
Security
Before even deploying our container, we should be completely aware of what is occurring within. By following recommended practices, most security risks can be reduced. The list of best practices is lengthy, so let's look at some of the things to do and not do.
- Any changes to the image or codebase should trigger a scan as part of this into a CI/CD pipeline. There are a lot of tools available to help us secure containers that can be leveraged to achieve this. We should also be mindful of any security patches released.
- We should make sure to apply the least privilege principle when building images and always look to create a non-root user with just enough permissions. As mentioned earlier in the article, we should also use established and trusted images from official sources e.g. Official Python image.
- We should build health checks into the containers
- Use COPY instead of ADD instructions when building containers. ADD let’s include a remote file.
- Do not store any secrets such as API keys or other credentials in the container. Instead, try to use an established secrets management solution that can provide secrets at runtime.
- Depending on how you choose to run containers, you may need to secure your runtime environment as well.
- Make your container immutable, eliminating the need for SSH or shell.
- Remove any editors such as vi, nano
- Mount read-only file systems, although if your container intends to handle file uploads, these can be handled better by using a cloud storage service.
Aside from the above, you should also consider using a good image scanning tool which can notify you of any security vulnerabilities as they are discovered.
Summary
To summarise, this article has looked at the refactoring/re-architecting approach to containers irrespective of the technology chosen. We also took a closer look at both the advantages and difficulties of containerization as they’re ephemeral and stateless.
The list of actions you can take to plan around the migration, and enhance your stack may be much more extensive and go into greater detail. Hopefully, this article has helped you better recognise some of the main issues we can face and also provided some helpful advice.
Additionally, you might want to assess the various run times you have at your disposal, such as Docker Swarm, Kubernetes, AWS Fargate, etc. These run times will have their own set of challenges.
If you want to know more about refactoring, why not read James Mason's blog Refactor before you rewrite.



/ebook%20modernizaci%C3%B3n%20+%20IA_guia%20CTOs/IA_modernisacion_form_bg.png?width=528&height=528&name=IA_modernisacion_form_bg.png)